
OCR読み取り設定
OCR読み取り設定は、DocuWorks文書から文字を読み取る場合に設定を行います。左上の処理名から、「OCR読み取り」を選択して、処理追加ボタンを押します。
OCR読み取りを使用して、振り分けを行う場合には、注意が必要です。OCR読み取りでは、文字の誤認が発生しますので、取り出した文字で、振り分けを行うような処理には向いていません。
読み取り精度の高いQRコードを使った方法でご利用することをお勧めします。
但し、対象となるDocuWorks文書からOCR処理を行わず、テキストを直接取り出せる場合(「OCR処理は行わずテキスト抽出のみ行う」にチェックを入れる場合)は、問題なく処理できます。
業務で使用する場合には、十分な検証を行ってからご利用願います。
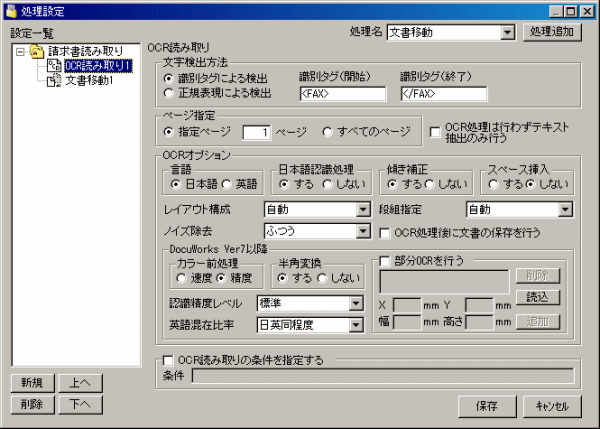
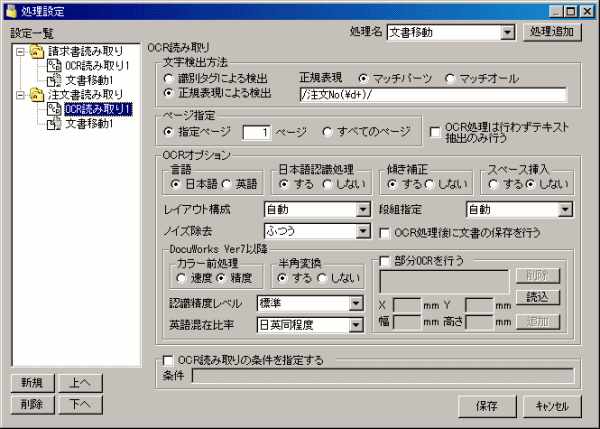
OCR読み取り設定では、下記の項目が設定できます。
開始タグと終了タグの間の文字を読み取るモードです。開始タグと終了タグが複数ペア存在した場合は、複数の文字検出が行われます。
検出した文字の結果は、内部変数に格納され、読み取りデータマクロにより参照可能となります。
例えば、処理「OCR読み取り1」で検出した1番目の検出データはマクロ
「
{%P_DATA(OCR読み取り1.1)}
」で参照可能です。
OCR読み取りでは、ページ全体の文字を読み取りますので、その中の特定の文字を認識するために、識別タグで囲われた文字を取得する方式になっています。
ここでは、その識別タグの開始タグと、終了タグを指定します。
例
読み取った文字が「 <START>ZX0001<END> 」の場合、開始タグに「 <START> 」終了タグに「 <END> 」を指定すると、「 ZX0001 」が検出できます。
正規表現(perl互換)による検出を行います。以下の2つのモードがあります。検索対象の文字列からマッチする文字列を複数取得したい場合は、「マッチオール」モードをご使用ください。
正規表現は、「/PATTERN/img」のように、スラッシュで囲い、最後にオプション文字を記述する書式になっています。(PATTERNは任意の正規表現文字列)
オプション文字の意味は以下の通りです。
| オプション | 内容 |
| g | グローバルマッチ。すべてのマッチパターンを検出します。マッチオールモードのみ有効になります。 |
| i | 大文字、小文字を区別しない。 |
| m | 文字列を複数行として扱う。 |
正規表現の詳細についてはPerlの参考書等を参照願います。
また、弊社にて、正規表現の設定を行うサービス(有料)もご用意しております。
正規表現の「( )」の中のパターンを取得するモードです。括弧の中身が内部変数に順に格納されます。
例えば、
/<FAX1>(.+?)<\/FAX1>.+<FAX2>(.+?)<\/FAX2>/
このような正規表現を書いた場合、パターンにマッチすると、
<FAX1>
と
</FAX1>
の間の文字が、
「
{%P_DATA(OCR読み取り1.1)}
」、
<FAX2>
と
</FAX2>
の間の文字が、
「
{%P_DATA(OCR読み取り1.2)}
」、で参照可能となります。
注:マッチパーツモードでは、オプション「g」には対応していません。
全ページを検索して結果が複数ページとなった場合、マクロ実行でページ単位に処理を行うかどうかで、番号で取得できる結果の内容が変わってきます。
例えばページ1に「Test001」「Test002」ページ2に「Test003」「Test004」があるとします。マッチパーツで正規表現に「/(Test\d+)/」を指定した場合、以下の様な結果となります。
マクロ実行でページ単位の処理をしない場合
| {%P_DATA(OCR読み取り1.1)} | {%P_DATA(OCR読み取り1.2)} | |
|---|---|---|
| マクロ結果 | Test001 | Test003 |
マクロ実行でページ単位の処理をする場合
| {%P_DATA(OCR読み取り1.1)} | {%P_DATA(OCR読み取り1.2)} | |
|---|---|---|
| ページ1のマクロ結果 | Test001 | 取得されません。 |
| ページ2のマクロ結果 | Test003 | 取得されません。 |
正規表現にマッチした全体部分が、内部変数に格納されます。
オプション「g」に対応していて、「g」を指定した場合は、複数のパターンマッチを行い結果を順に内部変数に格納します。
結果は、「
{%P_DATA(OCR読み取り1.1)}
」、
「
{%P_DATA(OCR読み取り1.2)}
」と、検出した個数分、番号で参照できます。
注:マッチオールモードでは正規表現「( )」で取得する部分検出には対応していません。
全ページを検索して結果が複数ページとなった場合、マクロ実行でページ単位に処理を行うかどうかで、番号で取得できる結果の内容が変わってきます。
例えばページ1に「Test001」「Test002」ページ2に「Test003」「Test004」があるとします。マッチオールで正規表現に「/Test\d+/g」を指定した場合、以下の様な結果となります。
マクロ実行でページ単位の処理をしない場合
| {%P_DATA(OCR読み取り1.1)} | {%P_DATA(OCR読み取り1.2)} | |
|---|---|---|
| マクロ結果 | Test001 | Test002 |
| {%P_DATA(OCR読み取り1.3)} | {%P_DATA(OCR読み取り1.4)} | |
|---|---|---|
| マクロ結果 | Test003 | Test004 |
マクロ実行でページ単位の処理をする場合
| {%P_DATA(OCR読み取り1.1)} | {%P_DATA(OCR読み取り1.2)} | |
|---|---|---|
| ページ1のマクロ結果 | Test001 | Test002 |
| ページ2のマクロ結果 | Test003 | Test003 |
OCRの読み取りを行うページを指定します。
指定ページを選択してページ番号を指定するか、全ページを選択します。
チェックを行うと、OCR処理を行いません。
対象となるDocuWorks文書がデジタル出力されているなどで、テキストを認識できる状態の場合などに使用します。
| 言語 | ||||
| 日本語 | OCR処理時に日本語モードで解析を行います。 | |||
| 英語 | OCR処理時に英語モードで解析を行います。 | |||
| 日本語認識処理 | ||||
| する | OCR処理時に日本語認識処理を行います。 | |||
| しない | OCR処理時に日本語認識処理を行いません。 | |||
| スペース挿入 | ||||
| する | OCR処理で結果にスペースを挿入します。 | |||
| しない | OCR処理で結果にスペースを挿入しません。 | |||
| 傾き補正 | ||||
| する | OCR処理で傾き補正を行います。 | |||
| しない | OCR処理で傾き補正を行います。 | |||
| レイアウト構成 | ||||
| 自動 | OCR処理で、構成を自動検出します。 | |||
| 表 | OCR処理で、表構成として処理を行います。 | |||
| 文章 | OCR処理で、文章構成として処理を行います。 | |||
| 段組指定 | ||||
| 自動 | OCR処理で、段組を自動検出します。 | |||
| 横書き一段 | OCR処理で、横書き一段として処理を行います。 | |||
| 横書き多段 | OCR処理で、横書き多段として処理を行います。 | |||
| 縦書き一段 | OCR処理で、縦書き一段として処理を行います。 | |||
| 縦書き多段 | OCR処理で、縦書き多段として処理を行います。 | |||
| ノイズ除去 | ||||
| 除去を行わない | OCR処理で、ノイズ除去を行いません。 | |||
| ふつう | OCR処理で、ノイズ除去をふつうに行います。 | |||
| 弱く | OCR処理で、ノイズ除去を弱く行います。 | |||
| 強く | OCR処理で、ノイズ除去を強く行います。 | |||
| OCR処理後に文書の保存を行う | ||||
| チェックすると、OCR処理後に文書の保存を行います。 | ||||
| 以下、DocuWorks7以上の場合のみ有効 | ||||
| カラー前処理 | ||||
| 速度 | OCR処理で、速度を優先します。 | |||
| 精度 | OCR処理で、認識率を優先します。 | |||
| 半角変換 | ||||
| する | OCR処理で、全角英数字を半角に変換します。 | |||
| しない | OCR処理で、半角変換を行いません。 | |||
| 認識精度レベル | ||||
| 速度優先 | OCR処理で、速度を優先して認識を行います。 | |||
| 標準 | OCR処理で、標準の認識を行います。 | |||
| 認識率優先 | OCR処理で、認識率を優先して認識を行います。 | |||
| 英語混在比率 | ||||
| 主に日本語 | OCR処理で、日本語優先の認識を行います。 | |||
| 日英同程度 | OCR処理で、日本語、英語をバランスよく認識します。 | |||
| 主に英語 | OCR処理で、英語優先の認識を行います。 | |||
チェックすると部分OCRを行います。OCRしたい領域のX,Y座標と幅、高さをミリ単位で入力します。入力後、追加ボタンを押すと、リストに入力した内容が追加されます。
座標を簡単に入力するために、あらかじめ、OCRしたい領域に矩形アノテーションを貼り付けた文書を用意し、その文書を読み取ることで、座標を自動入力する機能があります。
読込ボタンを押すと、文書を選択するダイアログが表示されますので、文書を指定してOKボタンを押します。すると、リストに座標情報が追加されます。
領域の指定は複数できますが、最大で20個までになっています。
リストから座標情報を削除するには、選択して削除ボタンを押します。
部分OCRで取得した文字が2つ以上ある場合、改行区切りでメモリに保存されますが、データ自体に改行が含まれる場合もありますので、その場合は項目毎の区別は不可となります。
どうしても指定した領域のみのデータを取得したい場合は、OCR読み取りを複数作成し、それぞれの処理では領域を一箇所のみ指定することになります。但し、OCR処理が個数分実行されるので、処理時間は増大します。
ユーザデータによる領域指定
OCR読み取りの前に、ユーザーデータに部分OCRの領域を指定できます。X座標、Y座標、幅、高さのユーザーデータをワンセットで作成します。ユーザデータにセットする内容は以下の通りです。
引数1:OCR処理名 + "_OcrOption_Rectangle"
引数2:ページ番号 + "_" + 領域番号 + "_" + x,y,w,hの何れか
引数3:X座標、Y座標、幅、高さの何れかの値。(1/100mm単位)
例えば、OCR処理1で行うページ1の領域1の指定を行うには、以下の様なユーザデータを事前にセットしておきます。
{%SET_USER_DATA(OCR読み取り1_OcrOption_Rectangle,1_1_x,4504)}
{%SET_USER_DATA(OCR読み取り1_OcrOption_Rectangle,1_1_y,2247)}
{%SET_USER_DATA(OCR読み取り1_OcrOption_Rectangle,1_1_w,9649)}
{%SET_USER_DATA(OCR読み取り1_OcrOption_Rectangle,1_1_h,1042)}
指定可能は領域数は、設定画面での領域指定と合わせて20個までになっています。20個以上指定した場合は、21個目以降が無視されます。
チェックするとOCR読み取りを行うかどうか条件を指定できます。条件には、マクロ書式を使用し、最終的に、「True」又は「False」の何れかの文字を返却するようにします。