OCR読み取り設定
OCR読み取り設定は、DocuWorks文書から文字を読み取る場合に設定を行います。XDW文書オープンの下か、ページの繰り返しの子ノードに追加します。
OCR読み取りを使用して、振り分けを行う場合には、注意が必要です。OCR読み取りでは、文字の誤認が発生しますので、取り出した文字で、振り分けを行うような処理には向いていません。 読み取り精度の高いQRコードを使った方法でご利用することをお勧めします。
対象となるDocuWorks文書からOCR処理を行わず、テキストを直接取り出せる場合(「OCR処理は行わずテキスト抽出のみ行う」にチェックを入れる場合)は、取得できる内容によって、特定のデータ取得や判定が確実にできます。
但し、テキスト抽出ができる場合でも、文字の並び順が印刷イメージ通りでなかったり、改行がすべて削除されていたりしますので、注意が必要です。
いずれにしても業務で使用する場合には、十分な検証を行ってからご利用願います。
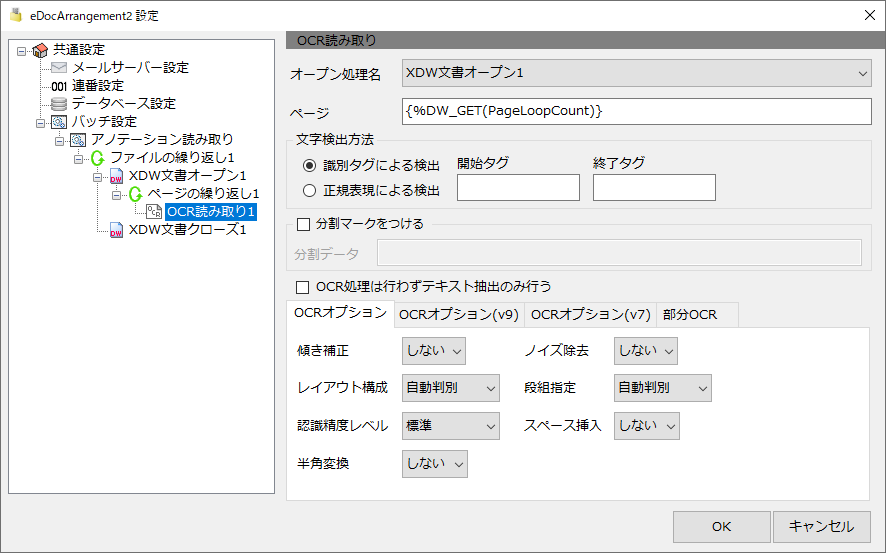
OCR読み取り設定では、下記の項目が設定できます。
文字検出方法
識別タグによる検出
開始タグと終了タグの間の文字を読み取るモードです。開始タグと終了タグが複数ペア存在した場合は、複数の文字検出が行われます。 検出した文字の結果は、ユーザーデータに格納され、ユーザーデータ取得マクロにより参照可能となります。
例えば、処理「OCR読み取り1」で検出した1番目の検出データはマクロ
「 {%GET_USER_DATA(OCR読み取り1,1)} 」で参照可能です。
開始タグ, 終了タグ
OCR読み取りでは、ページ全体の文字を読み取りますので、その中の特定の文字を認識するために、識別タグで囲われた文字を取得する方式になっています。
ここでは、その識別タグの開始タグと、終了タグを指定します。
例)
読み取った文字が「 <START>ZX0001<END> 」の場合、開始タグに「 <START> 」終了タグに「 <END> 」を指定すると、「 ZX0001 」が検出できます。
開始タグと終了タグを未入力にした場合、ページ全体の文字を取得します。
また、開始タグのみ指定した場合は、開始タグから末尾までの文字を取得します。終了タグのみ指定した場合は、先頭から終了タグまでの文字を取得します。
正規表現による検出
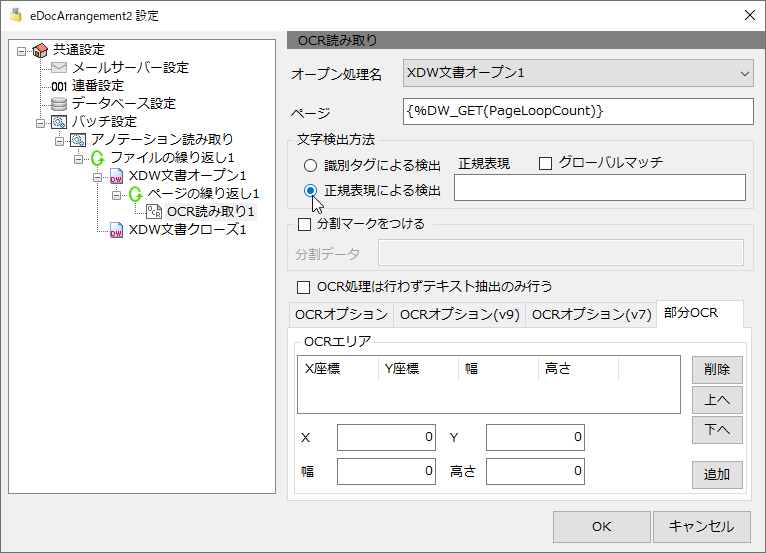
正規表現(.NET framework)による検出を行います。正規表現にキャプチャ記号「()」がある場合は結果にキャプチャした文字が格納されます。
オプションについては正規表現パターンの一部としてインラインで記述します。
「(?i)」のようにオプション文字を「(?」と「)」で囲います。
代表的なオプションは以下の通りです。
| オプション | 内容 |
|---|---|
| i | 大文字、小文字を区別しない。 |
| m | 文字列を複数行として扱う。 |
正規表現の詳細については.NET frameworkのWebサイト等を参照願います。
また、弊社にて設定支援を行うサービス(有料)もご用意しております。
グローバルマッチ
チェックを行うと、すべてのマッチパターンを検出します。
正規表現の例
以下のデータを検索する場合の例を紹介します。
配送指示書2020.08.20商品コード:120商品名:おいしい水数量:3商品コード:360商品名:緑茶数量:1納品日2020/09/01
正規表現に「^配送指示書」を指定した場合
| データ取得マクロ | 内容 |
|---|---|
| {%GET_USER_DATA(OCR読み取り1,1)} | 配送指示書 |
キャプチャ文字()を書いていないので、マッチする文字が結果に格納されます。この例の場合、先頭が「配送指示書」だった場合に「配送指示書」が格納されます。先頭が「配送指示書」ではない場合、結果は格納されず{%GET_USER_DATA_COUNT(OCR読み取り1)}の値は0となります。
正規表現に「納品日(\d{4}/\d{2}/\d{2})」を指定した場合
| データ取得マクロ | 内容 |
|---|---|
| {%GET_USER_DATA(OCR読み取り1,1)} | 2020/09/01 |
キャプチャ文字()を書いていますので、納品日の後ろの日付の部分が結果に格納されます。
正規表現に「納品日(\d{4})/(\d{2})/(\d{2})」を指定した場合
| データ取得マクロ | 内容 |
|---|---|
| {%GET_USER_DATA(OCR読み取り1,1)} | 2020 |
| {%GET_USER_DATA(OCR読み取り1,2)} | 09 |
| {%GET_USER_DATA(OCR読み取り1,3)} | 01 |
キャプチャ文字()を年、月、日の部分にそれぞれ書いていますので、結果は3つになります。
正規表現に「商品コード:(\d{3})商品名:(.+?)数量:(\d+)」を指定した場合
| データ取得マクロ | 内容 |
|---|---|
| {%GET_USER_DATA(OCR読み取り1,1)} | 120 |
| {%GET_USER_DATA(OCR読み取り1,2)} | おいしい水 |
| {%GET_USER_DATA(OCR読み取り1,3)} | 3 |
キャプチャ文字()を3つ書いていますので、結果は3つになります。対象データには複数の文字がありますが、グローバルマッチを指定していないと、最初に見つかったデータのみが結果として格納されます。
グローバルマッチをチェック状態にした場合、以下の様な結果になります。
| データ取得マクロ | 内容 |
|---|---|
| {%GET_USER_DATA(OCR読み取り1,1,1)} | 120 |
| {%GET_USER_DATA(OCR読み取り1,1,2)} | おいしい水 |
| {%GET_USER_DATA(OCR読み取り1,1,3)} | 3 |
| {%GET_USER_DATA(OCR読み取り1,2,1)} | 360 |
| {%GET_USER_DATA(OCR読み取り1,2,2)} | 緑茶 |
| {%GET_USER_DATA(OCR読み取り1,2,3)} | 1 |
グローバルマッチを指定した場合、ユーザーデータの階層が1つ増えます。GET_USER_DATAの2番目の引数がグループ番号になります。
分割マークをつける
チェックすると文字を検出したページをメモリに記憶します。ページ分割はファイル移動・コピー処理で行うことができます。
分割データ
ファイル移動・コピー処理で、分割を行う際に取得できるデータを指定します。
例えば、「{%GET_U(OCR読み取り1,1)}」と記述しておけば、ページ分割を行った際に、分割後のファイル名に取得した文字を使用することができるようになります。
OCR処理は行わずテキスト抽出のみ行う
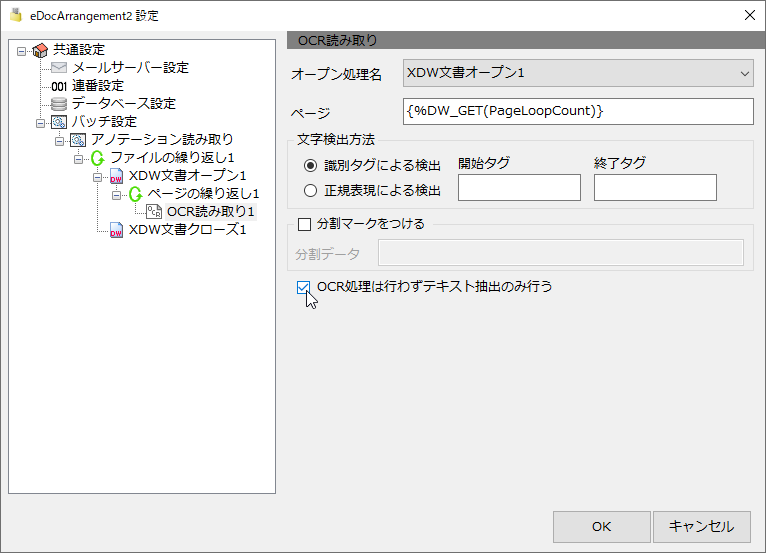
チェックを行うと、OCR処理を行いません。
対象となるDocuWorks文書がデジタル出力されているなどで、テキストを認識できる状態の場合などに使用します
OCRオプション
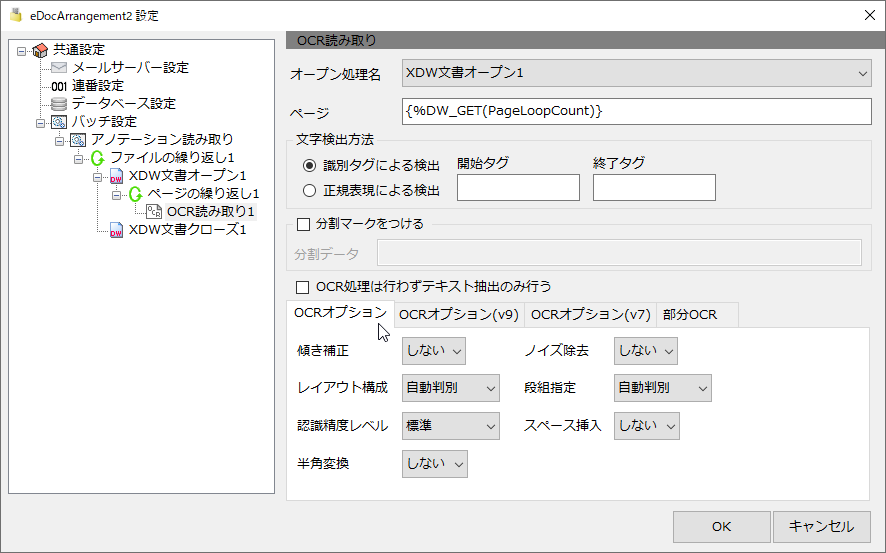
傾き補正
しない、する
OCR処理で傾き補正を「しない」か「する」かを選択できます。
ノイズ除去
しない、する
OCR処理でノイズ除去を「しない」か「する」を選択できます。
レイアウト構成
自動判別
OCR処理で、表構成として処理を行います。
文章
OCR処理で、文章構成として処理を行います。
表
OCR処理で、構成を自動検出します。
段組指定
自動判別
OCR処理で、段組を自動検出します。
横書き一段
OCR処理で、横書き一段として処理を行います。
横書き多段
OCR処理で、横書き多段として処理を行います。
縦書き一段
OCR処理で、縦書き一段として処理を行います。
縦書き多段
OCR処理で、縦書き多段として処理を行います。
認識制度レベル
標準
OCR処理で、標準の認識を行います。
認識率優先
OCR処理で、認識率を優先して認識を行います。
速度優先
OCR処理で、速度を優先して認識を行います。
スペース挿入
しない、する
OCR処理で結果にスペースを挿入「しない」か「する」かを選択できます。
半角変換
しない、する
OCR処理で、全角英数字を半角に変換「しない」か「する」かを選択できます。
OCRオプション(v9)
DocuWorks9以上でOCR処理を行う場合のオプション設定です。
DocuWorks9でOCR処理を行う場合は、ライセンス商品が必要になります。
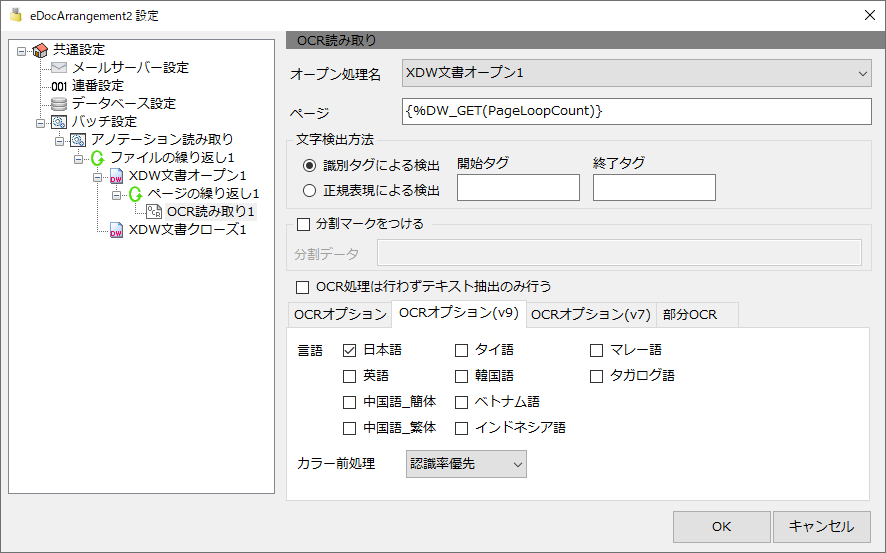
言語
認識を行う言語を選びます。
カラー前処理
認識率優先
OCR処理で、白黒変換を行い認識率を優先します。
速度優先
OCR処理で、白黒変換を行い速度を優先します。
カラーのまま
OCR処理で、カラーのまま認識を行います。
OCRオプション(v7)
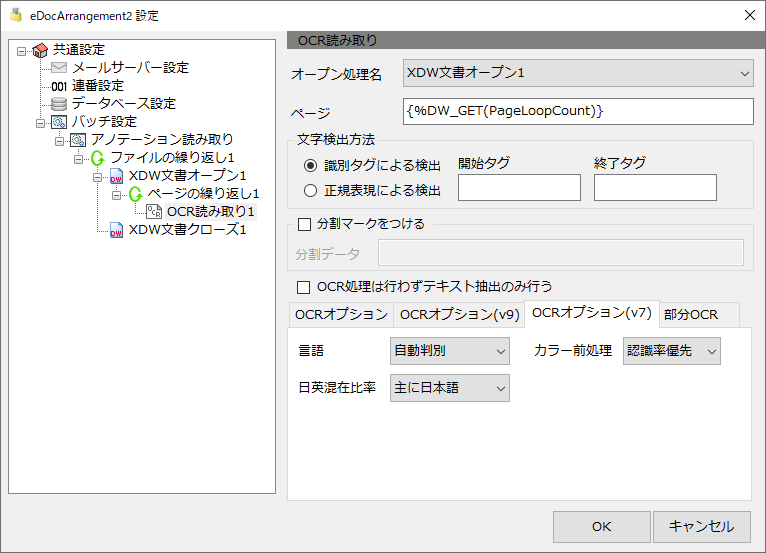
言語
自動判別
OCR処理で、言語の自動判別を行います。
日本語
OCR処理で、日本語モードで解析を行います。
英語
OCR処理で、英語モードで解析を行います。
カラー前処理
認識率優先
OCR処理で、白黒変換を行い認識率を優先します。
速度優先
OCR処理で、白黒変換を行い速度を優先します。
日本語混在比率
主に日本語
OCR処理で、日本語優先の認識を行います。
主に英語
OCR処理で、英語優先の認識を行います。
日英同程度
OCR処理で、日本語、英語をバランスよく認識します。
部分OCR
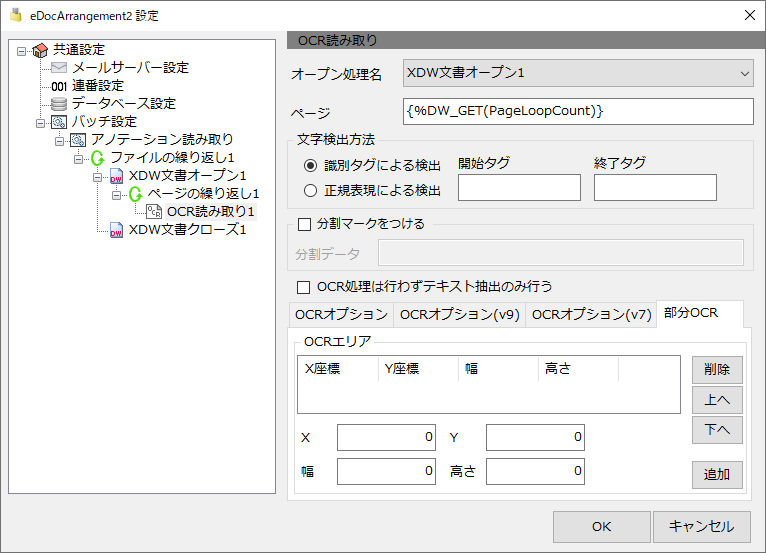
OCRしたい領域のX,Y座標と幅、高さをミリ単位で入力します。入力後、追加ボタンを押すと、リストに入力した内容が追加されます。
座標を簡単に入力するために、あらかじめ、OCRしたい領域に矩形アノテーションを貼り付けた文書を用意し、その文書を読み取ることで、座標を自動入力する機能があります。(XDW文書の1ページ目の矩形アノテーションを読み取ります。)
矩形アノテーションを貼り付けた文書をOCRエリアの一覧にドラッグ&ドロップすると、リストに座標情報が追加されます。
リストから座標情報を削除するには、選択して削除ボタンを押します。
部分OCRで取得した文字が2つ以上ある場合、改行区切りでメモリに保存されますが、データ自体に改行が含まれる場合もありますので、その場合は項目毎の区別は不可となります。
改行区切りで取得されるのはDocuWorksAPIの仕様なので、弊社では改善できません。
部分OCRのの指定が2つある場合、正規表現を以下のように指定すると、
([^\r\n]+)\r\n([^\r\n]+)
以下のようにユーザーデータから取得できます。
{%WRITE_LOG({%GET_U(OCR読み取り1,1)})}
{%WRITE_LOG({%GET_U(OCR読み取り1,2)})}
どうしても指定した領域のみのデータを取得したい場合は、OCR読み取りを複数作成し、それぞれの処理では領域を一箇所のみ指定することになります。但し、OCR処理が個数分実行されるので、処理時間は増大します。
ユーザーデータによる領域指定
OCR読み取りの前に、ユーザーデータに部分OCRの領域を指定できます。X座標、Y座標、幅、高さのユーザーデータをワンセットで作成します。ユーザーデータにセットする内容は以下の通りです。
引数1:OCR処理名 + "_OcrOption"
引数2:"Rectangle"
引数3:ページ番号(1~)
*を指定すると全てのページが対象となります。両方の指定がある場合はページ番号を優先して参照します。
引数4:領域番号(1~)
引数5:X座標(X)、Y座標(Y)、幅(Width)、高さ(Height)の何れか
引数6:X座標、Y座標、幅、高さの何れかの値。(1mm単位)
例えば、OCR処理1で行うページ1の領域1の指定を行うには、以下の様なユーザーデータを事前にセットしておきます。
{%SET_U(OCR読み取り1_OcrOption,Rectangle,1,1,X,45.04)}
{%SET_U(OCR読み取り1_OcrOption,Rectangle,1,1,Y,22.47)}
{%SET_U(OCR読み取り1_OcrOption,Rectangle,1,1,Width,96.49)}
{%SET_U(OCR読み取り1_OcrOption,Rectangle,1,1,Height,10.42)}